3. 머신러닝 모델 학습 프로세스
1. 업종별 예측활용 예시

서비스 >> 이털고객 예측
제조 >> 생산장비 고장예측
금융 >> 최적투자전략 예측
판매 >> 수요예측
보험 >> 과다청구여부 예측
광고 >> 출시상품의 반응 예측
2. 모델링의 핵심

예측하려는 대상인 Y를 여러개의 X를 대입한 함수식(모델)을 만듦으로써 예측한다
기존의 함수
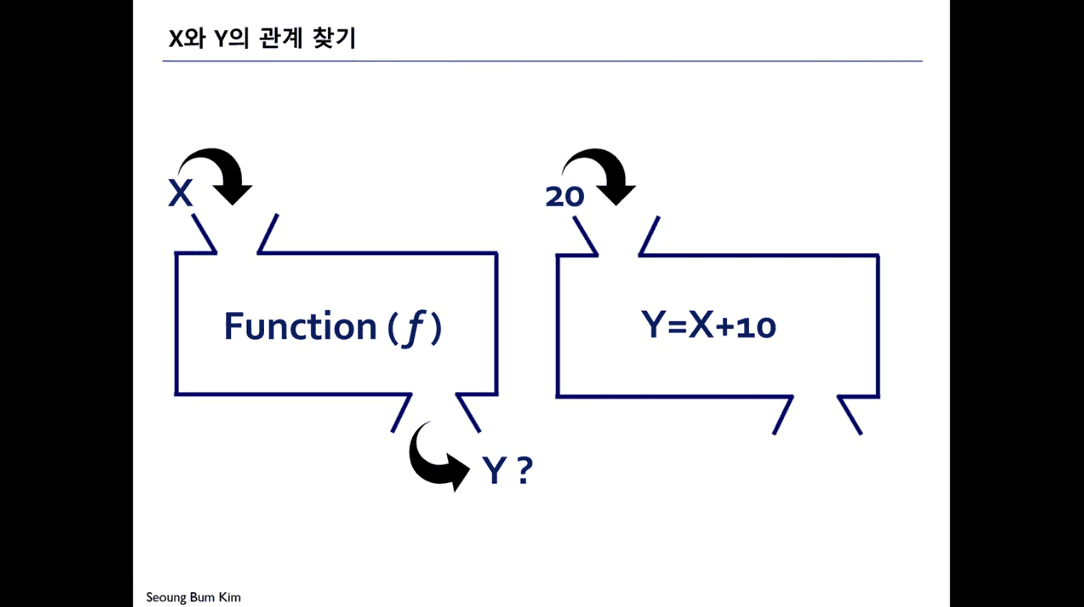
함수에 X를 대입해 Y에 해당하는 값을 찾아내기 위한 체계
모델링에서의 함수

수많은 X와 Y데이터가 이미 존재함
X와 Y를 연결짖는 함수(모델)을 만들어내는 것
X와 Y의 패턴 찾기

Y=X1+X2
모델링 예시) 됴요타 자동차 가격예측
주행거리, 마력, 용량데이터로 가격을 예측

Y = 가격
X1 = 주행거리
X2 = 마력
X3 = 용량
모델링의 핵심문제 1: 실제 가격과 완벽하게 맞는 예측이 가능할까?

실제로는 3개의 X 이외에 Y영향을 미치는 다른 요인들이 존재하기 떄문에 오차가 있음
오차를 나타내는 엡실론 기호
E,ε(그리스어:εˊψιλον엡실론)Ε
모델링의 문제 2: 각 X마다 Y에 미치는 영향(W)을 어떻게 구하나?

Y를 X1, X2의 합으로 표현하는데
각 X마다 어느정도 Y값에 영향을 미차나?
X의 변화가 Y의 변화에 얼마나 영향을 주나?
Wingth 를 나타내는 W를 설정함
w = 파라미터 = 모수 = 메게변수

X를 가지고 Y를 표현하는 메게체의 역할을 하는 변수 = W
좋은 모델을 만드는 과정

모델 (함수식)
Y는 X와 각 X들의 파라미터인 W를 곱한값과
X만으로 설명이 불가능한 Y의 일부(오차 ε)을 더해 구한다.
반대로 생각하면

(Testing Data의 Y)실제 Y와 모델(Training Data로 만든 함수식)에
(Testing Data의 X)를 넣어 도출된 예측 Y의 차= 오차값 ε
실제 Y와 예측Y의 차
오차 ε 가 적을수록 실제 현상을 잘 반영한 모델인 것
3. 손실함수 Loss Function
관측치마다의 개별적인 오차를 구하는 함수

각 오차값은 관측치 값인 n개 만큼 생성됨



>> 왜냐하면 각 i번쨰 오자 iε 마다 + 일수도 - 일수도 있기 때문에 상쇠되어버림
4. 비용함수 Cost Function
모델 전체가 가진 오차를 구하는 함수

제곱을 통해 오차의 -를 없애주고 합함으로써 전체 오차 구함
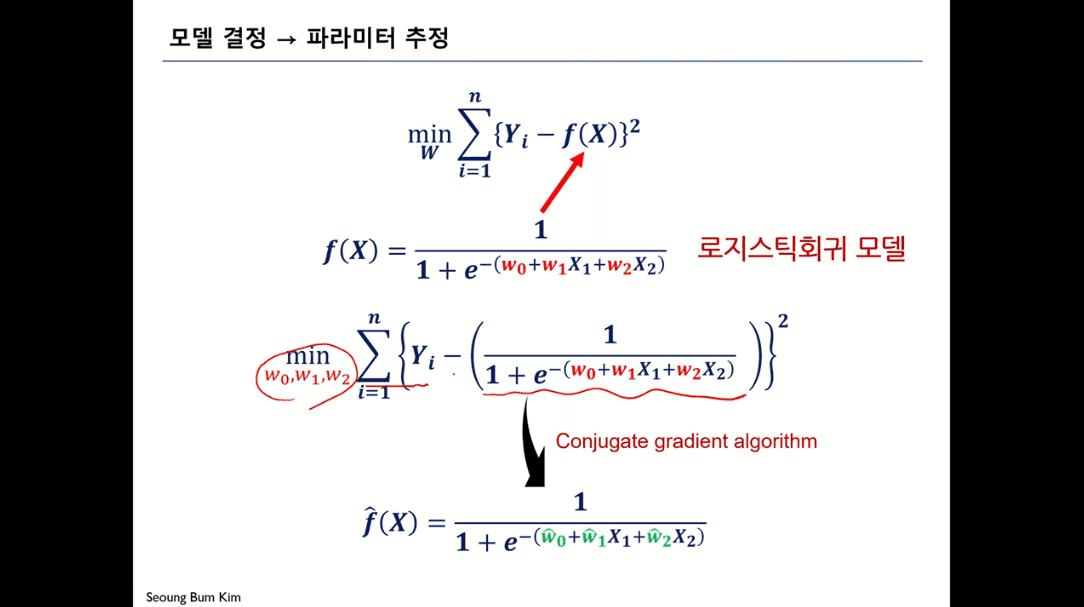
좋은 모델을 만들기 위해서


이러한 오차를 최소화하는 파리미터 W를 W햇으로 포현
모델별 파라미터 추정방법

각 모델마다 오차를 최소화하기 위한 알고리즘 존재



6. 모델링의 단계


나의 생각
모델에서 현재 가지고 있는 X요인 이외에 Y에 영향을 미치는 요인을 오차로 표현한다는 부분에서 이 오차값이 어떤 요인으로 분류되고 각 X마다 얼만큼에 파리미터를 가질 수 있는지 예측하는 것이 가능한지 궁금증이 들었다. 블로그 페이지를 정리하면서 생각해보니 현재 인공지능 기술로는 불가능할 것이다는 생각이 들었다. 인공지능은 인간이 입력한 데이터로써만 학습이 가능한데 만약 인공지능 스스로 인간이 입력한 데이터 이외에 추정 데이터를 만들어서 앞서말한 오차값을 여러 요인별로 분류하고 각 요인별 파라미터를 추정 할 수 있다면 오차를 극한으로 줄일 수 있을 것 같다. 더 배워서 내 생각이 가능한 것인지 실현해보고 싶다.